
EvaluationHarness
The EvaluationHarness is a powerful Haystack tool to evaluate your pipelines without needing to explicitly build a separate evaluation pipeline. Simply indicate which pipeline you want to evaluate, and the EvaluationHarness will handle it.
EvaluationHarness comes with built-in metrics and a standardized testing setup for default types of RAG pipelines, but you can also test more complex custom pipelines by providing extra parameters. The RAGEvaluationHarness class, derived from the Evaluation Harness, simplifies the evaluation process specifically for RAG pipelines. It comes with a predefined set of evaluation metrics, detailed in the RAGEvaluationMetric enum, and default types of RAG pipelines listed in the DefaultRAGArchitecture enum.
Finally, EvaluationHarness includes a tool to override default parameters, compare your pipelines with different parameters, and visually compare the data.
In short, these are the steps to use EvaluationHarness:
- Define the pipeline you want to evaluate.
- Create an EvaluationHarness object and pass it the pipeline.
- Prepare the evaluation data – the data depends on the selected evaluation metric.
- Run the EvaluationHarness with this data.
- Analyze the results using built-in tools that show you scores and metrics.
Evaluation Metrics
EvaluationHarness currently works with the following evaluation metrics:
- DOCUMENT_MAP: Document Mean Average Precision, evaluates how well the pipeline ranks relevant documents.
- DOCUMENT_MRR: Document Mean Reciprocal Rank, evaluates the rank position of the first relevant document in the retrieved list.
- DOCUMENT_RECALL_SINGLE_HIT: Evaluates whether at least one relevant document is retrieved.
- DOCUMENT_RECALL_MULTI_HIT: Evaluates the proportion of relevant documents that are successfully retrieved from the total number of relevant documents available.
- SEMANTIC_ANSWER_SIMILARITY: Evaluates the similarity between the generated answers and the ground truth answers using semantic similarity measures.
- FAITHFULNESS: Evaluates whether the generated answers are faithful to the content of the retrieved documents.
- CONTEXT_RELEVANCE: Evaluates the relevance of the context (retrieved documents) to the given query.
Default RAG Architectures
There are four RAG architectures available by default with EvaluationHarness which specify how different components in a RAG pipeline are organized and interact with each other.
- EMBEDDING_RETRIEVAL: This architecture includes a query embedder component named
query_embedderthat takestextas input. It also has a document retriever component named 'retriever' that outputs 'documents'. This pipeline is used for embedding-based retrieval of documents. - KEYWORD_RETRIEVAL: In this setup, the document retriever component named
retrievertakesqueryas input and outputsdocuments. It is designed for keyword-based retrieval of documents. - GENERATION_WITH_EMBEDDING_RETRIEVAL: Extends the EMBEDDING_RETRIEVAL setup by adding a response generator component named
generatorthat outputsreplies. It combines document retrieval with response generation using embeddings. - GENERATION_WITH_KEYWORD_RETRIEVAL: Extends the KEYWORD_RETRIEVAL setup by including a response generator component named
generatorthat outputsreplies. It combines keyword-based document retrieval with response generation.
To use the EvaluationHarness with one of these types of pipelines, first initialize RAGEvaluationHarness with your pipeline, its architecture type, and the metrics you want:
eval_harness = RAGEvaluationHarness(your_rag_pipeline,
rag_components=DefaultRAGArchitecture.GENERATION_WITH_EMBEDDING_RETRIEVAL,
metrics={
RAGEvaluationMetric.DOCUMENT_MAP,
RAGEvaluationMetric.DOCUMENT_RECALL_SINGLE_HIT,
RAGEvaluationMetric.FAITHFULNESS
})
Then, initialize the inputs for the EvaluationHarness. These inputs will be automatically passed to the RAG pipeline and the evaluation pipeline that the harness internally uses.
input_questions = random.sample(questions, 10)
eval_questions = [q["question"] for q in input_questions]
ground_truth_answers = [q["answers"]["text"][0] for q in input_questions]
ground_truth_documents = [
[
doc
for doc in document_store.storage.values()
if doc.meta["name"] == q["document_name"]
]
for q in input_questions
]
eval_harness_input = RAGEvaluationInput(
queries=eval_questions,
ground_truth_answers=ground_truth_answers,
ground_truth_documents=ground_truth_documents,
rag_pipeline_inputs={
"prompt_builder": {"question": eval_questions},
"answer_builder": {"query": eval_questions},
},
)
eval_run = eval_harness.run(inputs=eval_harness_input, run_name="eval_run")
Custom Pipeline
When you have a RAG pipeline that doesn't fit the standard architectures, you need to provide extra information to the EvaluationHarness so it understands how to interact with your pipeline's components.
First, identify which parts of your pipeline handle the query, retrieve documents, and generate the response.
For each of these key components, use RAGExpectedComponentMetadata to provide the EvaluationHarness with:
- The component's name in your pipeline.
- How to give it the query (input mapping).
- Where to get the results from (output mapping).
Let's say your pipeline has a custom query processor named "my_query_processor". You need to tell EvaluationHarness how to give it the query. In the metadata, you would specify:
query_processor_metadata = RAGExpectedComponentMetadata(
name="my_query_processor",
input_mapping={"query": "my_input_name"}
)
Here, query is a keyword that EvaluationHarness understands, and my_input_name is the actual name of the input in your custom component.
You need to provide similar metadata for the document_retriever and response_generator components.
Once you have the metadata for all three key components, create your EvaluationHarness object and provide this metadata in the rag_components parameter:
custom_eval_harness = RAGEvaluationHarness(
rag_pipeline=custom_rag_pipeline,
rag_components={
RAGExpectedComponent.QUERY_PROCESSOR: RAGExpectedComponentMetadata(
"query_embedder", input_mapping={"query": "text"}
),
RAGExpectedComponent.DOCUMENT_RETRIEVER: RAGExpectedComponentMetadata(
"retriever",
output_mapping={"retrieved_documents": "documents"},
),
RAGExpectedComponent.RESPONSE_GENERATOR: RAGExpectedComponentMetadata(
"generator", output_mapping={"replies": "replies"}
),
},
metrics={
RAGEvaluationMetric.DOCUMENT_MAP,
RAGEvaluationMetric.DOCUMENT_RECALL_SINGLE_HIT,
RAGEvaluationMetric.FAITHFULNESS
})
Working with Evaluation Results
You can view your evaluation run results either as a simple score report table with:
eval_run.results.score_report()
Resulting in:

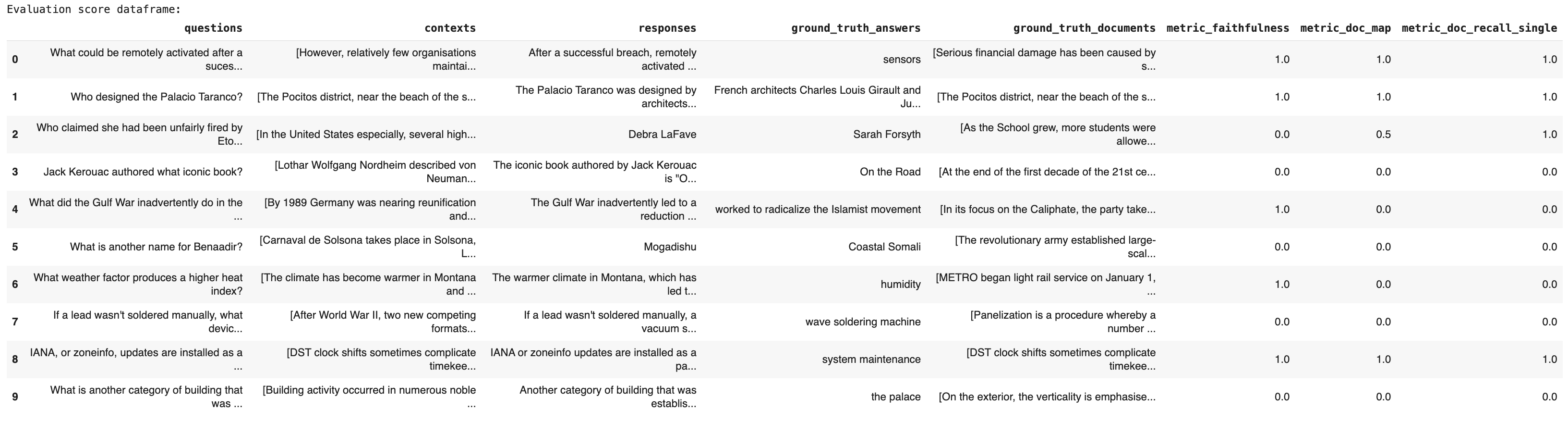
Or, you can get the results as a pandas dataframe and get a more detailed view:
eval_run.results.to_pandas()
Resulting in:
Overrides
Additionally, you can use RAGEvaluationOverrides and comparative_individual_scores_report to update various parameters in your pipeline and then evaluate different approaches. This will result in a table report with data for each pipeline run.
overrides = RAGEvaluationOverrides(your_rag_pipeline={
"generator": {"model": "gpt-4-turbo"},
})
eval_run_gpt4 = eval_harness.run(inputs=eval_harness_input, run_name="eval_run_gpt4", overrides=overrides)
print("Comparison of the two evaluation runs:")
eval_run.results.comparative_individual_scores_report(eval_run_gpt4.results)
Updated 2 months ago