
Hypothetical Document Embeddings (HyDE)
Enhance the retrieval in Haystack using HyDE method by generating a mock-up hypothetical document for an initial query.
When Is It Helpful?
The HyDE method is highly useful when:
- The performance of the retrieval step in your pipeline is not good enough (for example, low Recall metric).
- Your retrieval step has a query as input and returns documents from a larger document base.
- Particularly worth a try if your data (documents or queries) come from a special domain that is very different from the typical datasets that Retrievers are trained on.
How Does It Work?
Many embedding retrievers generalize poorly to new, unseen domains. This approach tries to tackle this problem. Given a query, the Hypothetical Document Embeddings (HyDE) first zero-shot prompts an instruction-following language model to generate a “fake” hypothetical document that captures relevant textual patterns from the initial query - in practice, this is done five times. Then, it encodes each hypothetical document into an embedding vector and averages them. The resulting, single embedding can be used to identify a neighbourhood in the document embedding space from which similar actual documents are retrieved based on vector similarity. As with any other retriever, these retrieved documents can then be used downstream in a pipeline (for example, in a Generator for RAG). Refer to the paper “Precise Zero-Shot Dense Retrieval without Relevance Labels” for more details.
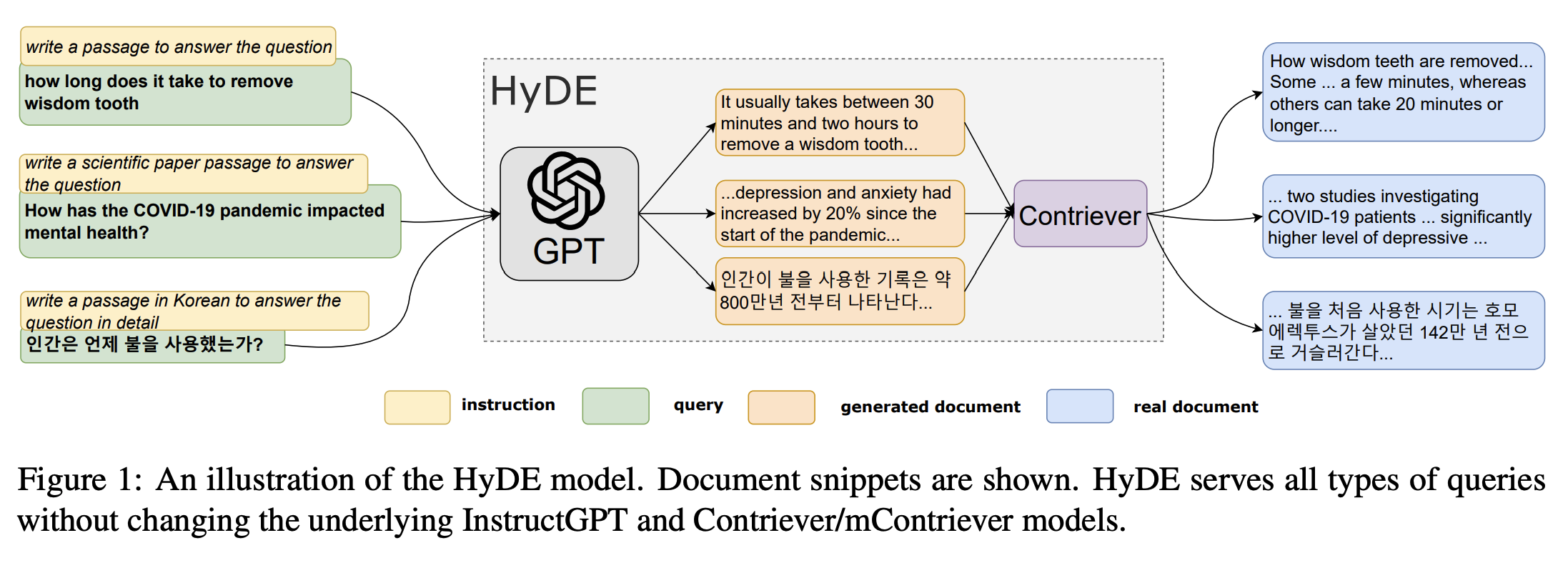
Source: Original Paper, Gao et al, https://aclanthology.org/2023.acl-long.99/
How To Build It in Haystack?
First, prepare all the components that you would need:
import os
from numpy import array, mean
from typing import List
from haystack.components.generators.openai import OpenAIGenerator
from haystack.components.builders import PromptBuilder
from haystack import component, Document
from haystack.components.converters import OutputAdapter
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
# We need to ensure we have the OpenAI API key in our environment variables
os.environ['OPENAI_API_KEY'] = 'YOUR_OPENAI_KEY'
# Initializing standard Haystack components
generator = OpenAIGenerator(
model="gpt-3.5-turbo",
generation_kwargs={"n": 5, "temperature": 0.75, "max_tokens": 400},
)
prompt_builder = PromptBuilder(
template="""Given a question, generate a paragraph of text that answers the question. Question: {{question}} Paragraph:""")
adapter = OutputAdapter(
template="{{answers | build_doc}}",
output_type=List[Document],
custom_filters={"build_doc": lambda data: [Document(content=d) for d in data]}
)
embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
embedder.warm_up()
# Adding one custom component that returns one, "average" embedding from multiple (hypothetical) document embeddings
@component
class HypotheticalDocumentEmbedder:
@component.output_types(hypothetical_embedding=List[float])
def run(self, documents: List[Document]):
stacked_embeddings = array([doc.embedding for doc in documents])
avg_embeddings = mean(stacked_embeddings, axis=0)
hyde_vector = avg_embeddings.reshape((1, len(avg_embeddings)))
return {"hypothetical_embedding": hyde_vector[0].tolist()}
Then, assemble them all into a pipeline:
from haystack import Pipeline
pipeline = Pipeline()
pipeline.add_component(name="prompt_builder", instance=prompt_builder)
pipeline.add_component(name="generator", instance=generator)
pipeline.add_component(name="adapter", instance=adapter)
pipeline.add_component(name="embedder", instance=embedder)
pipeline.add_component(name="hyde", instance=HypotheticalDocumentEmbedder())
pipeline.connect("prompt_builder", "generator")
pipeline.connect("generator.replies", "adapter.answers")
pipeline.connect("adapter.output", "embedder.documents")
pipeline.connect("embedder.documents", "hyde.documents")
query = "What should I do if I have a fever?"
result = pipeline.run(data={"prompt_builder": {"question": query}})
# 'hypothetical_embedding': [0.0990725576877594, -0.017647066991776227, 0.05918873250484467, ...]}
Here's the graph of the resulting pipeline:
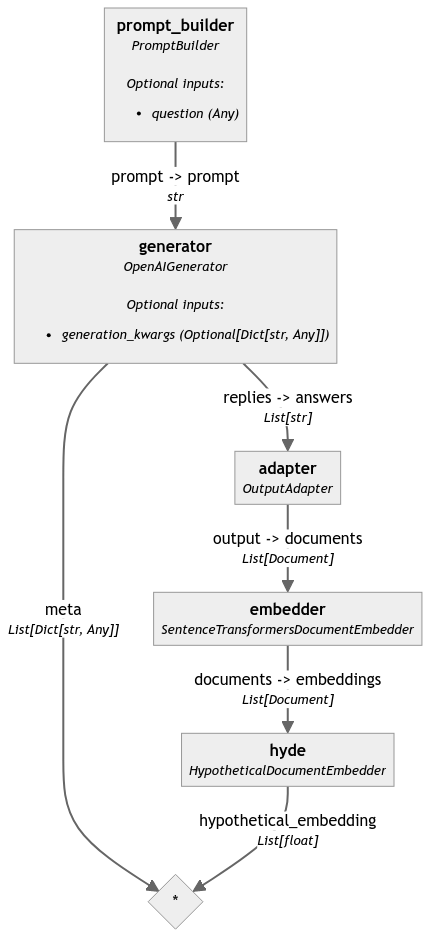
This pipeline example turns your query into one embedding.
You can continue and feed this embedding to any Embedding Retriever to find similar documents in your Document Store.
Additional References
📚 Article: Optimizing Retrieval with HyDE
🧑🍳 Cookbook: Using Hypothetical Document Embedding (HyDE) to Improve Retrieval
Updated about 1 month ago