
Components
Components are the building blocks of a pipeline. They perform tasks such as preprocessing, retrieving, or summarizing text while routing queries through different branches of a pipeline. This page is a summary of all component types available in Haystack.
Components are connected to each other using a pipeline, and they function like building blocks that can be easily switched out for each other. A component can take the selected outputs of other components as input. You can also provide input to a component when you call pipeline.run().
Stand-Alone or In a Pipeline
You can integrate components in a pipeline to perform a specific task. But you can also use some of them stand-alone, outside of a pipeline. For example, you can run DocumentWriter on its own, to write documents into a Document Store. To check how to use a component and if it's usable outside of a pipeline, check the Usage section on the component's documentation page.
Each component has a run() method. When you connect components in a pipeline, and you run the pipeline by calling Pipeline.run(), it invokes the run() method for each component sequentially.
Input and Output
To connect components in a pipeline, you need to know the names of the inputs and outputs they accept. The output of one component must be compatible with the input the subsequent component accepts. For example, to connect Retriever and Ranker in a pipeline, you must know that the Retriever outputs documents and the Ranker accepts documents as input.
The mandatory inputs and outputs are listed in a table at the top of each component's documentation page so that you can quickly check them:
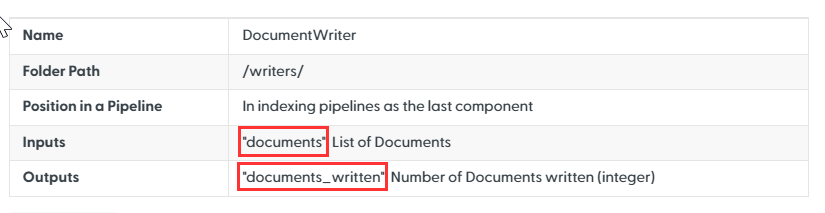
You can also look them up in the code in the componentrun() method. Here's an example of the inputs and outputs of TransformerSimilarityRanker:
@component.output_types(documents=List[Document]) # "documents" is the output name you need when connecting components in a pipeline
def run(self, query: str, documents: List[Document], top_k: Optional[int] = None):# "query" and "documents" are the mandatory inputs, additionally you can also specify the optional top_k parameter
"""
Returns a list of Documents ranked by their similarity to the given query.
:param query: Query string.
:param documents: List of Documents.
:param top_k: The maximum number of Documents you want the Ranker to return.
:return: List of Documents sorted by their similarity to the query with the most similar Documents appearing first.
"""Warming Up Components
Components that use heavy resources, like LLMs or embedding models, additionally have a warm_up() method. When you run a component like this on its own, you must run warm_up() after initializing it, but before running it, like this:
from haystack import Document
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
doc = Document(content="I love pizza!")
doc_embedder = SentenceTransformersDocumentEmbedder() # First, initialize the component
doc_embedder.warm_up() # Then, warm it up to load the model
result = doc_embedder.run([doc]) # And finally, run it
print(result['documents'][0].embedding)If you're using a component that has the warm_up() method in a pipeline, you don't have to do anything additionally. The pipeline takes care of warming it up before running.
The warm_up() method is a nice way to keep the init() methods lightweight and the validation fast. (Validation in the pipeline happens when connecting the components but before warming them up and running.)
Updated about 5 hours ago