
Hayhooks
Hayhooks is a web application you can use to serve Haystack pipelines through HTTP endpoints.
Quickstart
Install the Package
Start by installing the Hayhooks package:
pip install hayhooks
The hayhooks package ships both the server and the client component, and the client is capable of starting the server. From a shell, start the server with:
$ hayhooks run
INFO: Started server process [44782]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:1416 (Press CTRL+C to quit)
Check Status
From a different shell, you can query the status of the server with:
$ hayhooks status
Hayhooks server is up and running.
Deploy a Pipeline
Time to deploy a Haystack pipeline. The pipeline must be in YAML format as the output of pipeline.dump(). If you don't have one at hand, you can use one from Hayhooks repository. From the root of the repo:
$ hayhooks deploy tests/test_files/test_pipeline_01.yml
Pipeline successfully deployed with name: test_pipeline_01
Another call to status should confirm your pipeline is ready to serve requests:
$ hayhooks status
Hayhooks server is up and running.
Pipelines deployed:
- test_pipeline_01
API Schema
Hayhooks will use introspection to set up the OpenAPI schema according to the inputs and outputs of your pipeline. To see how this works, let's get the pipeline diagram with:
$ curl http://localhost:1416/draw/test_pipeline_01 --output test_pipeline_01.png
The downloaded image should look like this:
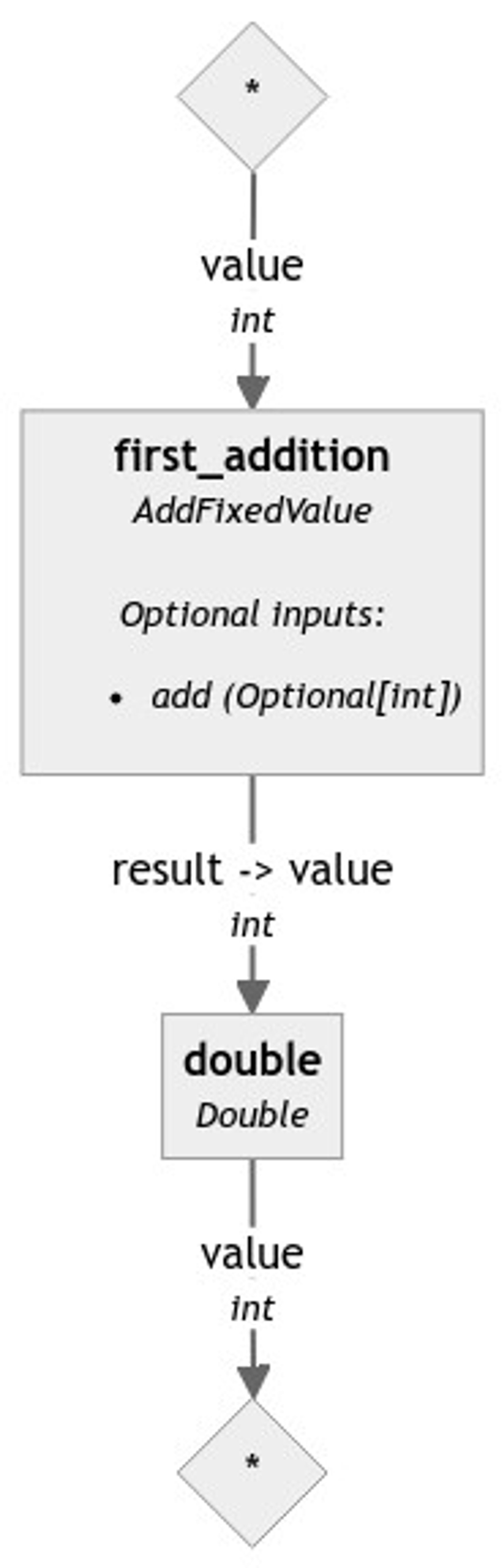
As you can see, in order to start, the pipeline requires an input of type int named value, and, optionally, we can pass another input of type int named add. At the end of the run, the pipeline will return an output of type int named result.
If you open a browser at http://localhost:1416/docs#/, you should see two schemas. The first one is for the Request, where we'll pass the pipeline inputs (note how add is optional):
Test_pipeline_01RunRequest
first_addition
value* integer
add (integer | null)
Another one is for the Response, where we'll receive the pipeline results:
Test_pipeline_01RunResponse
double
value* integer
Run the Pipeline
At this point, knowing the schema we can run our pipeline with an HTTP client:
$ curl -X 'POST' \
'http://localhost:1416/test_pipeline_01' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"first_addition": {
"value": 19
}
}'
{"double":{"value":42}}%
Undeploy the Pipeline
Hayhooks attempts to do as much bookkeeping as possible without restarting the server. For example, to free up resources, you can undeploy the pipeline directly from the client:
$ hayhooks undeploy test_pipeline_01
Pipeline successfully undeployed
Docker setup
Instead of launching the server in a separate shell like we did in the Quickstart above, you can run it in a Docker container :
$ docker run --rm -p 1416:1416 deepset/hayhooks:main
...
If you want to build the container yourself:
$ cd docker
$ docker buildx bake
...
Updated over 1 year ago